fairseq로 wav2vec2 finetuning하기
1. 필요한 파일 준비 (train, test, valid)
- .tsv
- (audio 파일들의 절대경로) + '\t' + (frame 수)
- 도커에서 실행하려고 할때는 맨 윗줄에 공통경로를 적어줘야 함 !!
- (audio 파일들의 절대경로) + '\t' + (frame 수)

- .ltr (or .phn)
- 인식하고자 하는 문장을 letter (ltr) 단위 혹은 phoneme (phn) 단위로 전사한 텍스트로 이루어진 파일
- 중국어의 성모, 운모+성조를 하나의 음소로 보고 음소인식 수행
- 인식하고자 하는 문장을 letter (ltr) 단위 혹은 phoneme (phn) 단위로 전사한 텍스트로 이루어진 파일

- .wrd
- 인식하고자 하는 문장을 word (wrd) 단위로 전사한 텍스트로 이루어진 파일
- 중국어의 경우 띄어쓰기가 없기 때문에 character (한자) 단위로 나누어도 됨
- 음소인식 task의 경우에는 wrd 파일과 phn 파일이 같아도 상관 없음
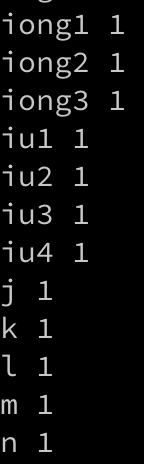
- dict.ltr.txt (or dict.phn.txt)
- (음소 or 단어) + ' ' + '1'
- 주어진 텍스트에 대한 dictionary
import soundfile as sf
import re
## audio path, chinese character sentence로 구성된 csv 파일 로드
with open('/data/jihyeon1202/nia/nia_ch/ch.csv', 'r') as f:
lines = f.readlines()
## import g2p module -> kakaobrain의 g2p 사용
from g2pM import G2pM
model = G2pM()
vowels = ['a', 'e', 'i', 'o', 'u'] # 중국어의 성모와 운모를 나누기 위해 모음 지정
ph_tsv = []
for line in lines:
wav_path = line.split(',')[0]
ch_sent = line.split(',')[-1]
## text preprocessing
ch_sent = ch_sent.lstrip().replace('\n', '')
ch_sent = re.sub('[-=+,#\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·。]', '', ch_sent)
## apply g2p
phoneme = model(ch_sent, tone=True, char_split=False)
split_cv = []
for j in range(len(phoneme)):
phoneme_str = str(phoneme[j])
phoneme_list = list(phoneme_str)
for k in range((len(phoneme_list))):
if phoneme_list[k] in vowels:
consonant = phoneme_str[:k]
vowel = phoneme_str[k:]
split_cv.append(consonant)
split_cv.append(vowel)
break
phoneme = ' '.join(p for p in split_cv) ## 성모 운모+성조 의 형태로 텍스트 분할
new_line = wav_path + '\t' + phoneme + '\n'
ph_tsv.append(new_line)
## wav_path, g2p 적용된 문장으로 구성된 tsv 파일 생성
with open('/data/jihyeon1202/nia/nia_ch/nia_4.tsv', 'w') as f:
f.writelines(ph_tsv)
## create wav2vec2 data
with open('/data/jihyeon1202/nia/nia_ch/nia_4.tsv', 'r') as f:
lines = f.readlines()
tsv_list = []
phn_list = []
wrd_list = []
dict_list = []
for line in lines:
if 'wav' in line:
fname = line.split('\t')[0]
sent = line.split('\t')[-1]
length = sf.info(fname).frames ## get audio frames
tsv_line = fname + '\t' + str(length) + '\n'
phn_line = sent
wrd_line = phn_line ## 이 task에서는 phn과 wrd가 동일해서 이렇게 적용, phn과 wrd가 다를 경우 wrd에 대한 코드 작성 필요
phns = sent.split(' ') ## phonemes로 이루어진 문장을 공백을 기준으로 잘라 개별 phoneme을 얻음
phns[-1] = phns[-1][:-1] ## '\n' 제거
dic_list = []
for phn in phns:
dict_line = phn + ' 1\n'
if dict_line in dic_list: pass
else: dic_list.append(dict_line)
tsv_list.append(tsv_line)
phn_list.append(phn_line)
wrd_list.append(wrd_line)
dict_list.append(dic_list)
else: pass
## dictionary의 중복 제거
dict_list = list(set(dict_list))
dict_list.sort()
## 파일 생성
with open('/data/jihyeon1202/nia/fairseq_data/test.tsv', 'w') as f:
f.writelines(tsv_list)
with open('/data/jihyeon1202/nia/fairseq_data/test.phn', 'w') as f:
f.writelines(phn_list)
with open('/data/jihyeon1202/nia/fairseq_data/test.wrd', 'w') as f:
f.writelines(wrd_list)
with open('/data/jihyeon1202/nia/fairseq_data/dict.phn.txt', 'w') as f:
f.writelines(dict_list)
2. yaml 파일의 parameter 설정
# @package _group_
common:
fp16: true ## half precision 사용 -> 16bit만을 사용하여 수를 표현함으로써 계산량과 메모리 사용량을 줄임
log_format: tqdm ## tqdm: 프로그램 진행상황을 그림으로 볼 수 있게 해주는 파이썬 라이브러리
log_interval: 200 ## log progress every N batches (when progress bar is disabled)
tensorboard_logdir: /workspace/data/nia/fairseq_data/logs ## tensorboard 진행상황 확인할 경로 지정
checkpoint:
save_interval: 1000 ## save a checkpoint every N epochs
save_interval_updates: 1000 ## save a checkpoint (and validate) every N updates
keep_interval_updates: 1 ## keep the last N checkpoints saved with –save-interval-updates
no_epoch_checkpoints: true ## only store last and best checkpoints
best_checkpoint_metric: wer
save_dir: /workspace/data/fairseq_data/checkpoints
task:
_name: audio_finetuning
data: /workspace/data/fairseq_data/commonvoice/
normalize: true
labels: phn
dataset:
num_workers: 16
max_tokens: 1280000
skip_invalid_size_inputs_valid_test: true ## ignore too long or too short lines in valid and test set
validate_after_updates: 10000 ## dont validate until reaching this many updates
validate_interval_updates: 1000 ## validate every N updates
valid_subset: valid
distributed_training:
ddp_backend: legacy_ddp ## DistributedDataParallel backend, Possible choices: c10d, fully_sharded, legacy_ddp, no_c10d, pytorch_ddp, slowmo
distributed_world_size: 4 ## total number of GPUs across all nodes
criterion:
_name: ctc ## choose appropriate loss
zero_infinity: true ## Whether to zero infinite losses and the associated gradients
optimization:
max_update: 25000 ## force stop training at specified update
lr: [0.00001] ## learning rate for the first N epochs
sentence_avg: true ## normalize gradients by the number of sentences in a batch (default is to normalize by number of tokens)
update_freq: [4] ## update parameters every N_i batches, when in epoch i
optimizer:
_name: adam
adam_betas: (0.9,0.98) ## coefficients used for computing running averages of gradient and its square
adam_eps: 1e-08 ## term added to the denominator to improve numerical stability (default: 1e-08)
lr_scheduler:
_name: tri_stage
phase_ratio: [0.1, 0.4, 0.5]
final_lr_scale: 0.05
model:
_name: wav2vec_ctc
w2v_path: /workspace/data/fairseq_data/xlsr_53_56k.pt
apply_mask: true
mask_prob: 0.5
mask_channel_prob: 0.1
mask_channel_length: 64
layerdrop: 0.1
activation_dropout: 0.1
feature_grad_mult: 0.0 ## multiply feature extractor var grads by this
freeze_finetune_updates: 0
3. Finetuning
fairseq-hydra-train \
distributed_training.distributed_port=$PORT \
task.data=/path/to/data \
model.w2v_path=/path/to/model.pt \
--config-dir /path/to/fairseq-py/examples/wav2vec/config/finetuning \
--config-name <yaml file name>fairseq-hydra-train --config-dir /workspace/data/fairseq_data/config/ --config-name finetune-cv_cn- task.data, model.w2v_path 등은 yaml 파일에서 지정해주었기 때문에 finetuning 할 때 별도로 지정 안 해줘도 됨
참고자료
https://fairseq.readthedocs.io/en/latest/command_line_tools.html
Command-line Tools — fairseq 0.12.2 documentation
--arch, -a Possible choices: transformer_tiny, transformer, transformer_iwslt_de_en, transformer_wmt_en_de, transformer_vaswani_wmt_en_de_big, transformer_vaswani_wmt_en_fr_big, transformer_wmt_en_de_big, transformer_wmt_en_de_big_t2t, transformer_from_pre
fairseq.readthedocs.io
https://github.com/facebookresearch/fairseq/blob/main/examples/wav2vec/README.md
GitHub - facebookresearch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Facebook AI Research Sequence-to-Sequence Toolkit written in Python. - GitHub - facebookresearch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
github.com
새로운 도커 컨테이너에서 'distutils'의 version 문제가 발생하면
https://yjs-program.tistory.com/259
AttributeError: module 'distutils' has no attribute 'version'
pip install setuptools==59.5.0 이유는 모르겠지만 이게 도움이 되는 것 같다. +) 참고자료 : https://stackoverflow.com/questions/70520120/attributeerror-module-setuptools-distutils-has-no-attribute-version AttributeError: module 'setuptoo
yjs-program.tistory.com
setuptools를 버전을 바꿔주자